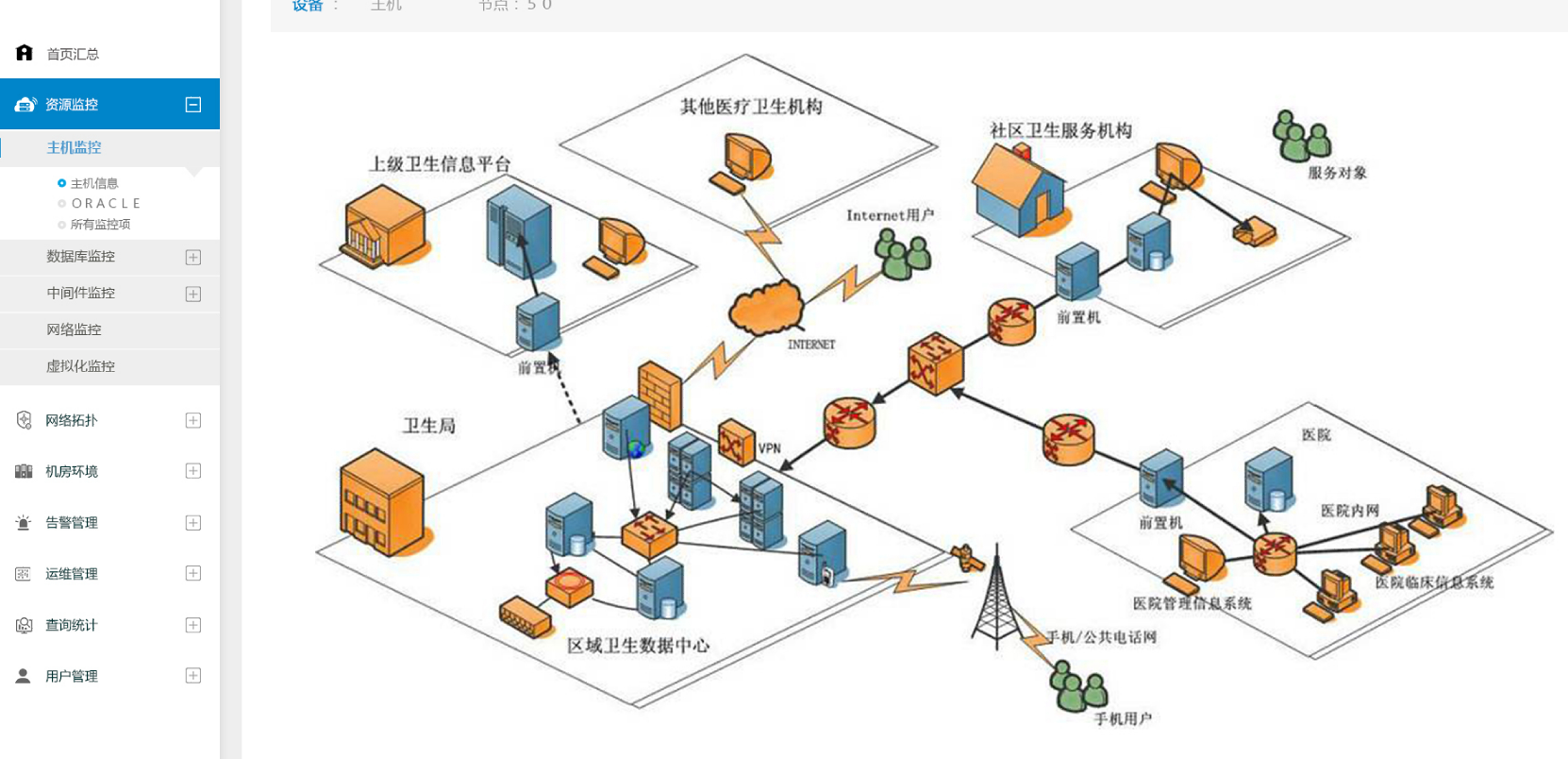
近年来随着人社行业信息化技术的迅速发展,特别是在社会保障卡发行后,各人社的五险系统、异地就医、内外公共服务、互联网业务各项软硬件建设高速增长,对安全性、实时性、系统维护要求更高。
人力社保信息系统越来越多、越来越庞大,也越来越复杂,同时业务对信息系统支撑力度要求也越来越高,为确保信息系统安全、平稳的运行,做到对系统运行故障的及时发现,尽快处理。因此建设综合运维管理系统是很有必要的。
然而这一切,传统的IT运维服务软件无法满足这样的要求,需要有一套对人社行业知根知底的应用系统运维监控平台,来迎接新的挑战和要求,使人社用户的运维工作越来越轻松,并且在运维服务的过程中,能够实现量化管理,不断提升综合的运维管理能力。
应用运维监控平台总体目标是确保数据安全和系统平稳运行。具体有三方面:一是实现对硬件设备、网络的实时监控,达到对人社信息中心的网络、设备、应用系统等资源的可视、可控、可管理,从而加强系统的监控与维护能力;二是提高系统维护工作的质量和综合运维管理水平;三是实现业务实时监控,为业务系统提供有利保障,进一步提升信息安全防护能力。具体目标如下:
(一)预防为主。实现信息中心运维管理的主动化和体系化,通过实时的监测和分析发现系统潜在的问题和风险,实现主动式运维管理,最大程度减少事故的发生,实现运维管理的流程化。
(二)快速反应。确保信息中心设备和应用系统正常、安全、高效运行,方便信息中心随时了解各个系统的运行情况,在系统发生故障时能够迅速反应,及时获取相关的告警,快速定位异常位置和报告故障发生可能的原因。
(三)机房环境实时监控。实时监控信息中心机房环境运行情况。
应用运维监控平台从功能结构上为三层结构,具有良好的可扩展能力,可以自定义增加多种监控设备,整个系统体系结构展现如下图:
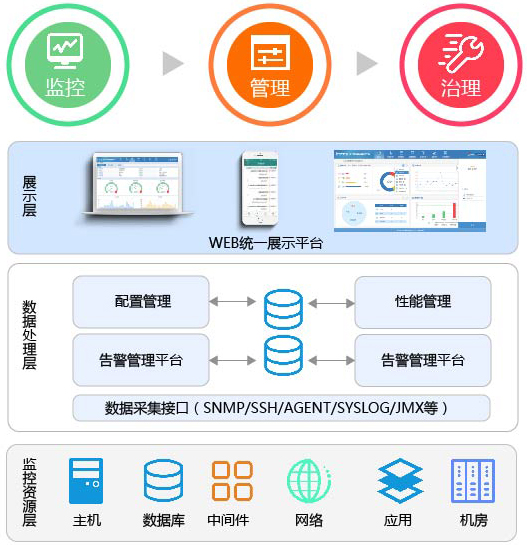
监控资源层
监控资源层提供网络监控、主机系统监控、数据库监控、网络监控、应用、机房环境等监控。
数据处理层
数据处理层利用全面集中监控,统一管理的理念实现各项监控工具的信息汇聚与集中存储,包括:监控告警、性能与状态信息。以及配置信息,系统用户权限管理的处理等。
展现层
展示层通过统一WEB的方式提供对各种监控性能指标、网络拓扑结构的展示。
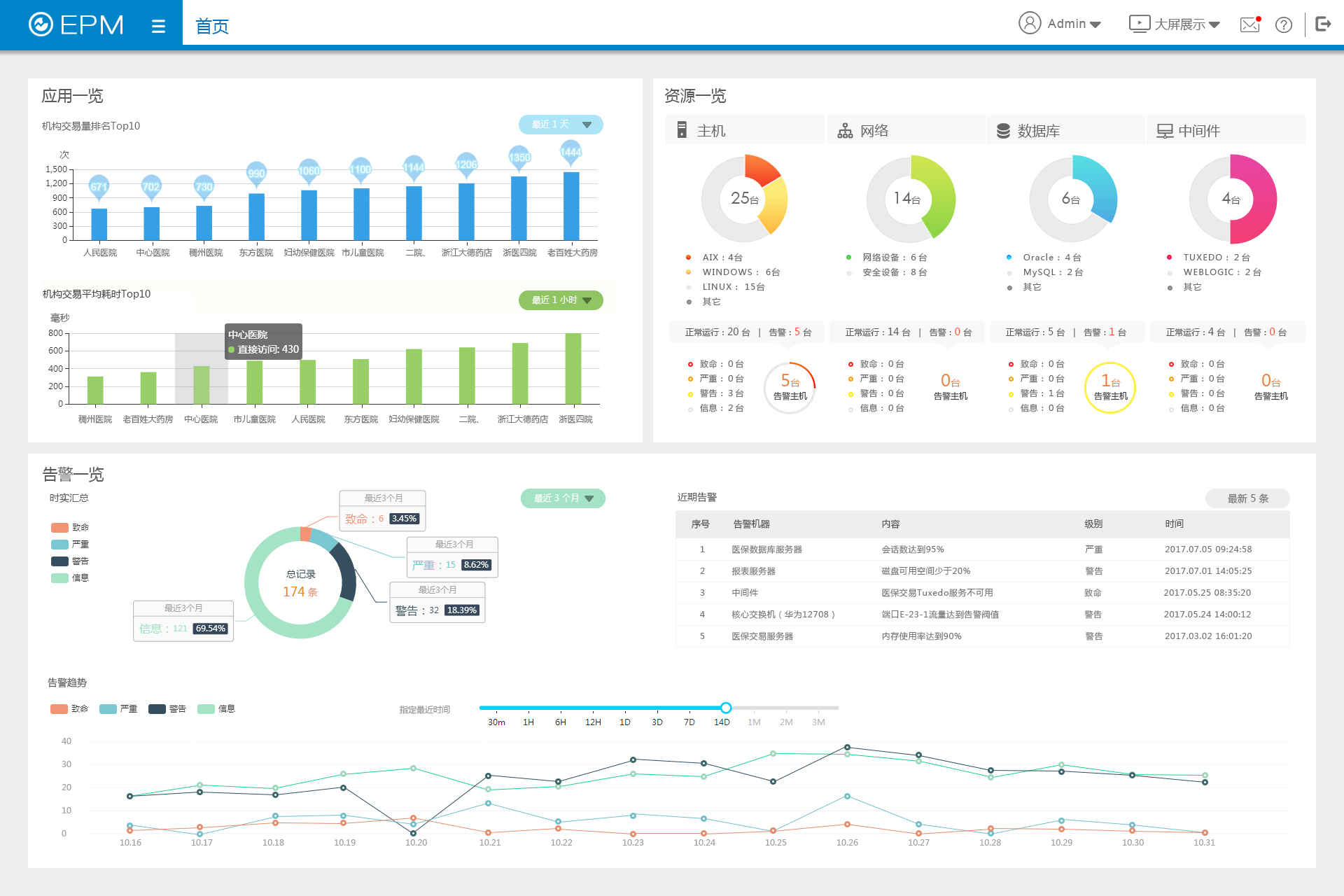
网新恩普应用运维监控平台以可视化的方式提供业务和资源的性能趋势分析,从而可以预知业务瓶颈,变被动响应为主动预防,直接减少业务故障的发生,提升业务部门的满意度;另一方面,恩普公司从业务角度提供业务的架构视图、业务故障根源分析视图,业务故障可直接分析定位,并关联展示资源的各类信息、资源关系可视化、资源状态可视化,有效支撑故障原因分析,缩短故障分析时间,从而提升业务保障能力;恩普应用运维监控平台提供了各类资产统计视图、资源拓扑视图等,资源及容量情况、资产投入情况、资源关系情况可轻松全面掌握,随时可提供给其他部门或者领导各类统计报告。
1、网络系统监控
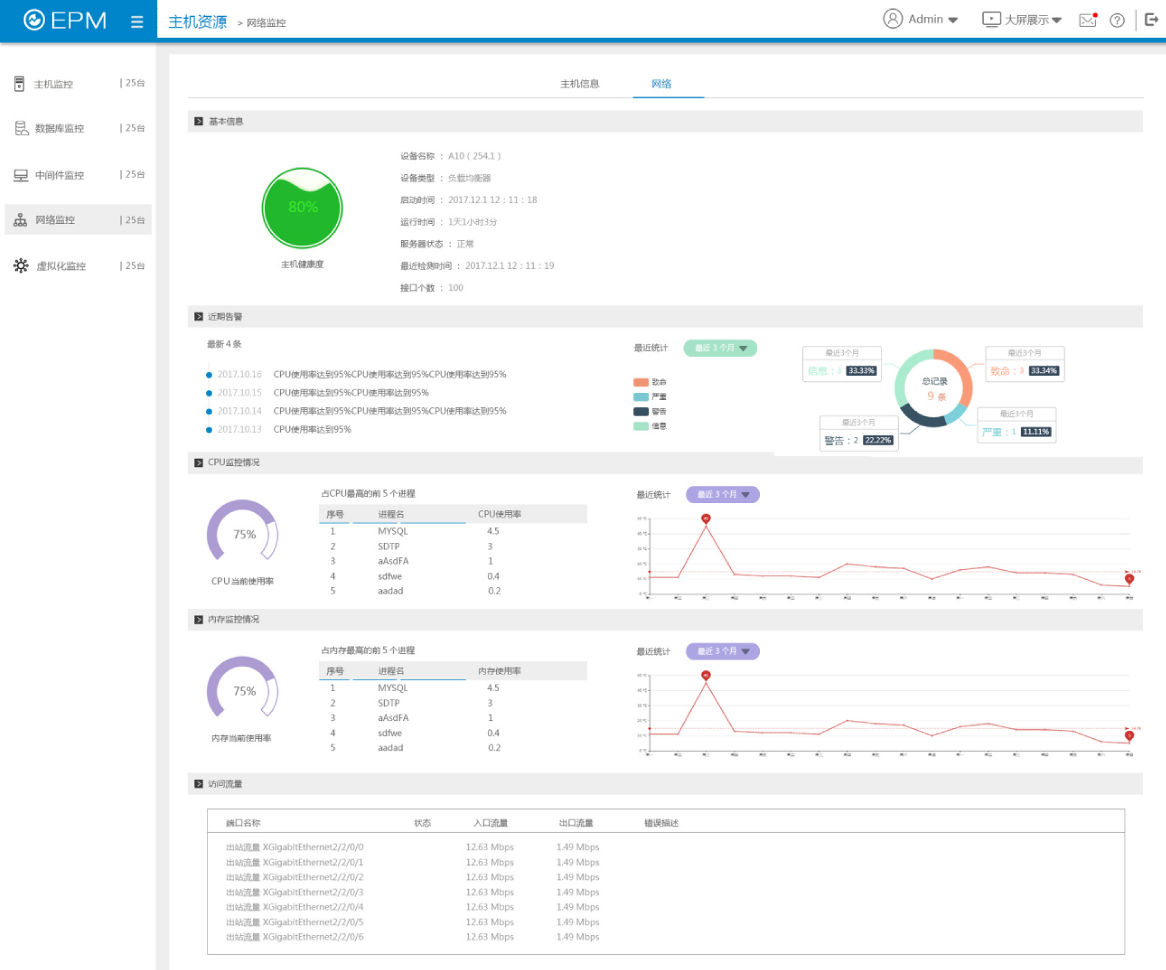
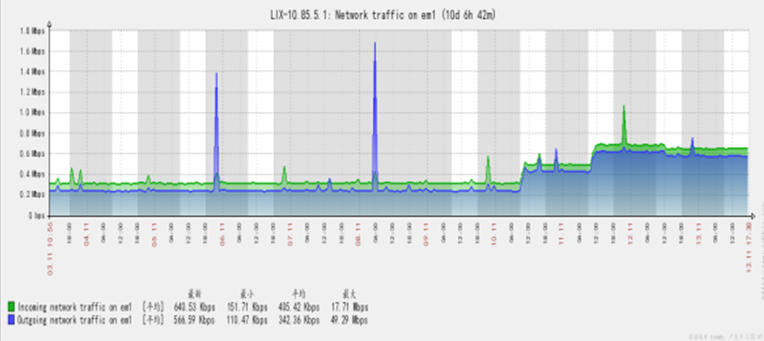
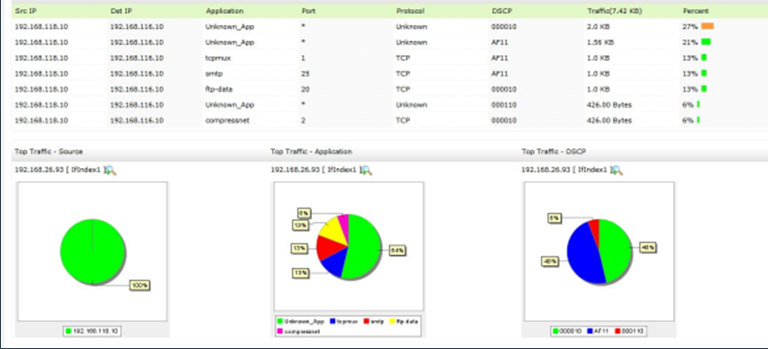
实现网络设备、网络安全设备的在线状态、CPU利用率、内存大小、设备日志、设备各种表信息的监控。对网络线路运行状态监控,包括线路联通性、线路响应时间、线路流量、线路带宽利用率、线路错包率、线路丢包率等信息。对网络设备接口状态进行监管,包括接口状态、接口流量性能等信息。持续监视、报告网络的运行情况,发现异常及时告警;设备故障与链路阻断告警,设备与链路性能告警,异常流量告警等。
2、主机系统监控
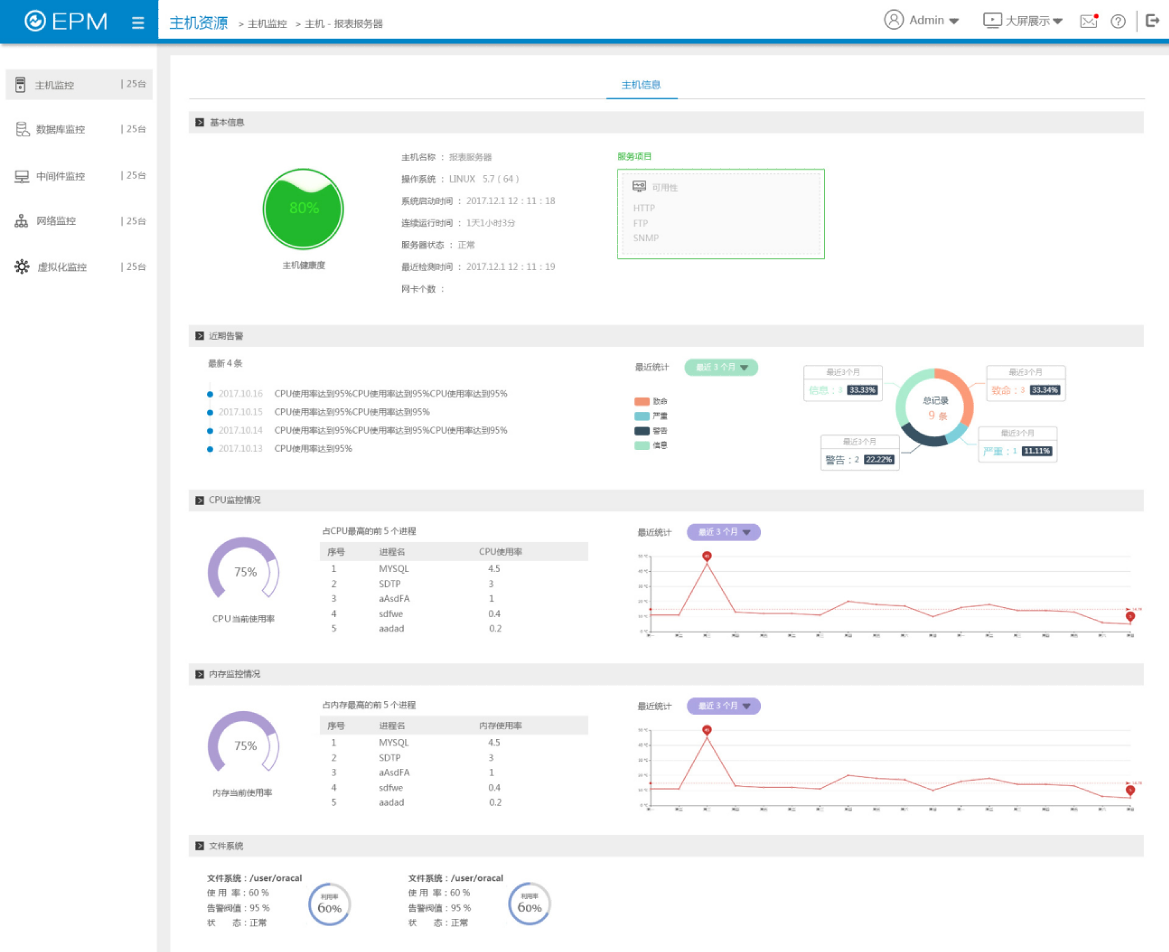
实现对HP-UX、AIX、Solaris主机、Windows主机、Linux主机运行状况监控,包括主机的在线状态、CPU利用率、内存大小及利用率、磁盘空间大小及利用率、主机上关键进程状态及其对CPU和内存占用情况、提供关键服务状态、提供所安装软件详细列表、主机的设备信息、ARP信息、SYSLOG 信息、主机的网络接口流量、丢包和错包率等信息。
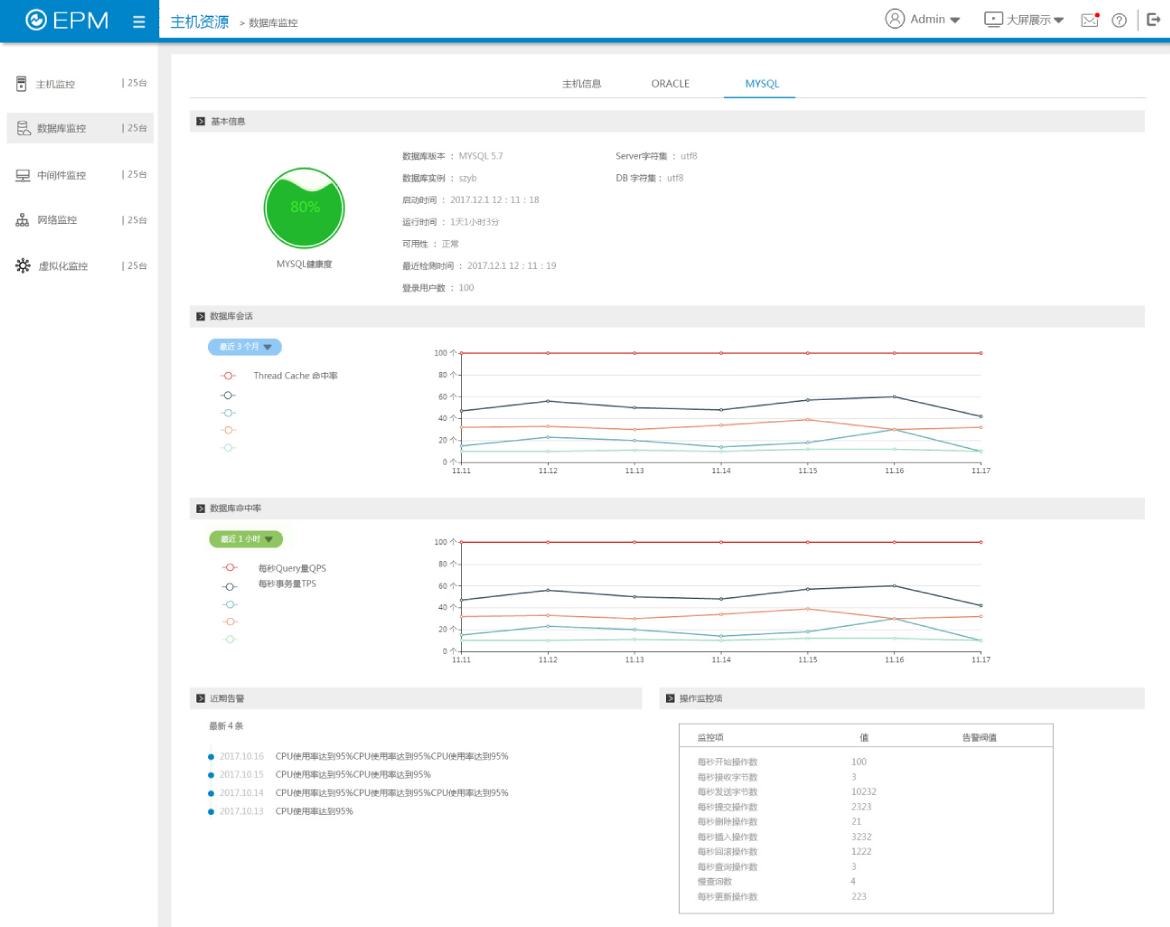
3、数据库监控
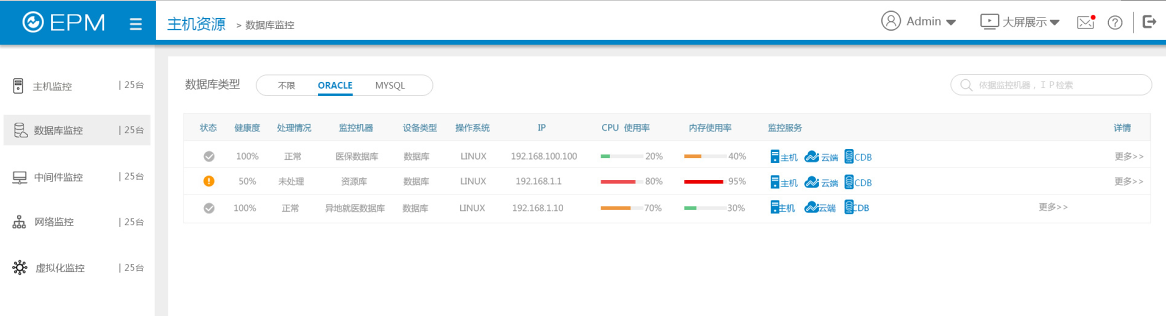
实现对Oracle、Sybase、Informix、DB2、SQLServer、MySQL等主流数据库的监控管理。监视数据库运行状态,包括数据库进程、监听状态、例程状态、控制文件、数据库日志文件等信息;对数据库资源监视,包括数据库CPU、内存配置(SGA信息、PGA信息)、缓冲区命中率等信息;对数据库存储资源监视,包括数据库文件系统、数据库表空间、数据库表、数据库空间、文件空间等;对数据库Session信息、锁信息、数据库用户等信息监控。
在参数到达门限值时通过网管系统的事件管理机制发出警告,报告给数据库管理员,以便及时采取措施。
4、中间件监控
实现对Weblogic、Tuxedo、Tomcat、JBOSS等主流中间件的运行状态监控。
监控队列信息、监控JDBC连接池信息、监控Web应用信息、JVM堆信息、服务信息。
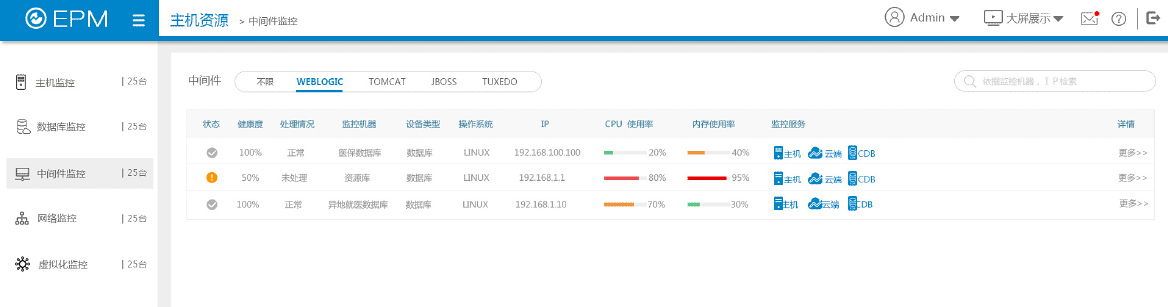
监控运行状态、服务启动时间、安装目录、总安装目录、运行配置、JVM版本号、JVM可用内存、JVM最大内存、JVM总的内存、线程。
监控服务启动、关闭时有无错误信息,服务已经处理的请求数、服务正在处理的交易;监控各类队列参数:当前队列的所有请求的参数和、实际请求数、平均队列长度、队列所在机器的LMID等;监控客户端信息,包括客户端状态、启动的交易数、提交的交易数、中断的交易数等;监控交易信息,包括交易名、交易函数名、交易已经执行的次数、交易当前状态。
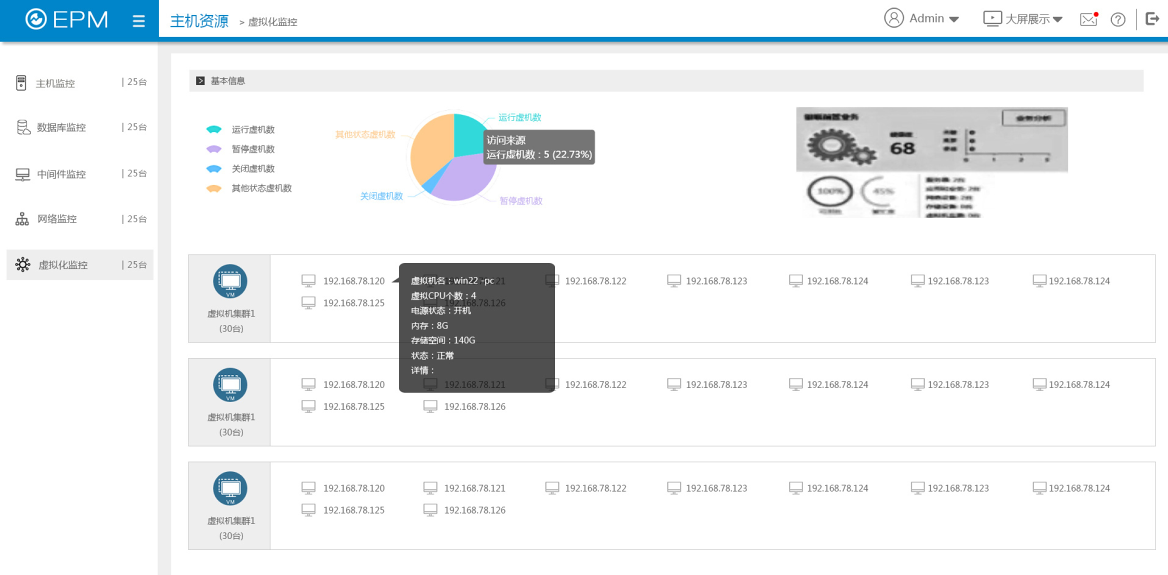
5、虚拟化监控
实现虚拟化监控,如虚拟机主机的主机信息以及虚拟池下面的虚拟主机的主机信息。
6、系统用户与日志管理
为保证安全性,所有登录的用户均采用统一的安全认证。通过用户和角色控制每个管理员的权限,实现用户和角色的多对多管理,严格划分职责和权限。超级管理员可以创建角色和用户,并为不同的角色分配不同的功能权限和管理域权限。一个角色可以包含多个用户,一个用户可以属于多个角色 ,告警与用户挂钩。
-
感知大屏展现
大屏展现功能主要是面向中、大型用户将其所监控的各种网络设备、应用、服务及业务等资源的实时运行情况以平面化的图像界面进行展现。主要包括资源告警一览、交易一览、数据库一览、中间件一览、机房监控一览等功能。系统以加强运维人员的实际体验为出发点,通过实时的图像界面、简明扼要的图标,有效避免了运维人员因整天面对枯燥的文字和简单的数字而产生的视觉疲劳感,帮助运维人员更加全面、直观的掌握所关注的每个核心网络设备(包括安全设备、机房设备)、应用、服务及业务系统等资源当前运行情况等。
-
智能轮询机制
应用运维监控平台提供智能的轮询机制,对于不同的设备、不同的接口、不同的指标都可以设置不同的轮询或监视周期,让运维人员能够均衡每个设备采集的敏感度、时间间隔与设备性能之间进行有效匹配。对于用户特别重要的核心设备可以将其监视周期设置的比较短(如1秒,10秒),而对于不太重要设备则可以将监视周期设置的比较长(如300秒、甚至600秒)。一般情况下,核心设备的处理能力比较高,当设备一旦中断运维人员需要及时了解设备的异常情况。如果轮询周期设的比较短的话,设备一旦出问题可马上通知到运维人员。对于非核心设备,通常它的处理能力比较低,如果将它的轮询周期设置的比较短,频繁的轮循会对设备的CPU、内存等将产生一定的影响。另外,非核心设备作为边缘设备,如果发生问题对企业的整个业务影响也并非很大,所以通过智能的轮询机制可以为企业关键的IT资源予以更多的关注,从而保障核心资源服务的持续可用性。
-
异常依赖
应用运维监控平台可以将链路、网络设备、服务、应用及业务等资源之间按照物理的逻辑关系建立依赖树(一种依赖关系)。在这种情况下,当管理系统服务器的上联设备发生故障时,系统将自己判断整个数据流是否被堵塞及被堵塞的位置等。若系统检测不到其它所有的设备的异常,则将自动对管理系统服务器的上联设备产生相关异常等级的告警。在管理系统服务器上联网络设备接口关闭之后,系统会在拓扑图上的非真正宕机的设备上以“?”显示,在上联真正有故障的网络设备图标旁以“禁止”符号表示,避免所有网络设备、服务器、应用等大范围同时进行“虚假”告警。从而帮助运维人员准确定位故障源,不仅大大减少了运维人员对故障猜测与分析的时间,而且有效提高了运维效率!
-
告警敏感度
应用运维监控平台提供告警敏感度功能,通过告警敏感度的设定并对IT资源进行自动监测。当IT资源的指标在某一时刻达到一个异常峰值时,对于此现象只是一次偶发情况,不能算是一次异常,系统则不会产生告警。当它连续违反阈值出现三次以后,系统才会产生一个异常。系统通过告警敏感度则可以过滤掉峰值情况(也叫毛刺现象),从而屏蔽不重要的告警信息,减少告警干扰,并帮助运维人员将精力集中在关键问题上。
-
知识库联动
应用运维监控平台具有强大的知识库功能,知识库提供了各种异常情况所致原因、解决方法与操作步骤等具体参考信息。当异常发生时,在系统中只需点击该异常信息,打开详细信息页面,即可自动关联到系统的知识库,显示与该异常相关的知识。网络管理人员可以在知识库中查找与异常有关的条目,寻找解决方案。随着新的“知识”不断加入,知识库会越来越强大,对用户的帮助也会更大。